Transformer for Computer Vision
Introduction
본 포스트는 철저히 내가 공부한 내용을 쉽게 리마인드 하기위해 작성하였다. 앞뒤 내용 빼고 몸통만 설명하므로 자세한 설명이 필요한 분들은 다른 곳을 찾아보시길 바란다.
1. Attention Is All You Need
| Title | Attention Is All You Need |
|---|---|
| Authos | Ashish Vaswani외 6명 (모두 Google Brain) |
| Publisher | NIPS, 2017 |
주요 참고 자료: 허민석 https://www.youtube.com/watch?v=mxGCEWOxfe8&list=PLVNY1HnUlO26qqZznHVWAqjS1fWw0zqnT
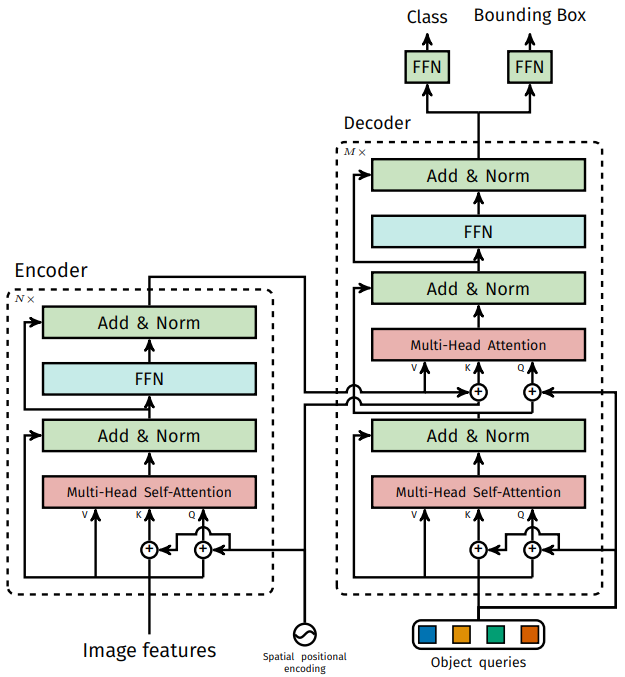
1.1. Model Architecture
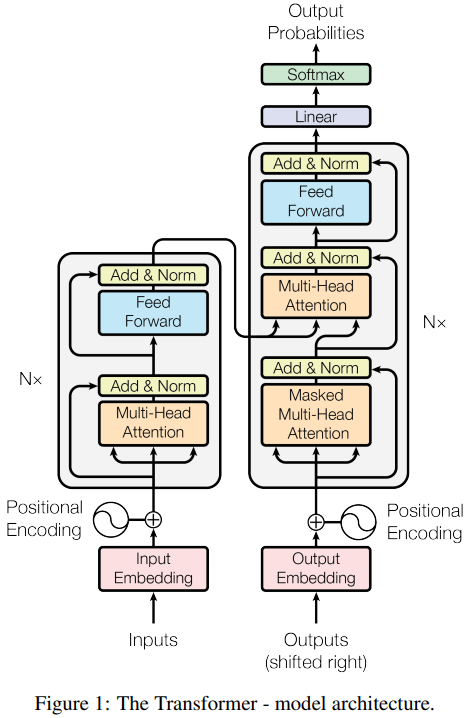
예시를 들 때 편의상 번역기를 가정하고 예시를 만든다. Transformer가 번역기에서 좋은 결과가 나왔을 뿐만 아니라 가장 전형적인 sequence-to-sequence 모델이기 때문이다. 여기서는 “GNU is Not Unix”를 “그누는 유닉스가 아니다”로 번역하는 경우를 생각해본다.
A. Encoder
A.1 Input
‘GNU’, ‘is’, ‘Not’, ‘Unix’ 각각을 word2vec 같은 워드 임베딩을 통해 벡터로 만든다. 전체 입력의 길이를 \(L_{in}(=4)\)이라 한다. 입력을 하나씩 순서대로 임베딩 하는게 아니라 한번에 모두 임베딩을 계산해야 한다. 임베딩의 결과는 \(M (L_{in},d_{model})\) 이다.
Input Embedding에는 순서를 알려주기 위해 다음과 같은 Positional Encoding을 더해준다.

A.2. Linear
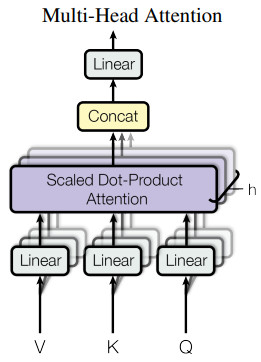
인코더에는 모든 입력이 한번에 들어간다. \((L_{in},d_{model})\) 모양의 입력이 Query, Key, Value 세 갈래로 들어간다. 각각은 linear 레이어를 통과하여 서로 다른 특성을 학습하게 한다. Multi-Head Attention에서는 여러개의 attention을 위한 다른 입력을 만들어야 하기 때문에 \(h(=8)\)개의 Head가 있다면 사실상 linear 레이어의 출력 차원이 \(h\)배가 되는 셈이다.
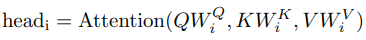
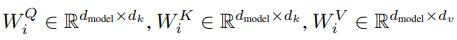
Query, Key, Value 모두 처음에는 \((L_{in},d_{model})\) 이었는데 각 head의 linear 레이어를 통과하면 Query, Key는 \((L_{in},d_k)\)가 되고 Value는 \((L_{in},d_v)\) 가 된다. Value의 dimension을 다르게 할 수도 있지만 논문에서는 \(d_k=d_v=d_{model}/h=64\) 로 모두 같게 한다.
실제 구현을 한다면 \(h\)개의 head를 위해 따로 linear 레이어를 구성하기 보다는 출력 차원이 \(h * d_k\)인 하나의 linear 레이어로 최적화 할 것 같다.
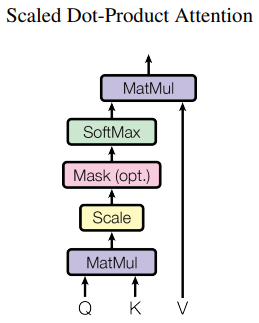
A.3. Self-attention
Self-attention 내부에는 학습 파라미터가 없다. “Scaled Dot-Product Attention”그림에 나온대로 단순히 아래 식을 계산할 뿐이다. \(\sqrt{d_k}\) 로 나눠주는 이유는 학습 효율을 개선하기 위함이다. Dimension이 늘어날수록 전반적으로 dot product(\(QK^T\))의 크기 편차가 커지고 그에 따라 softmax결과로 0에 가까운 값이 많이 나와서 gradient도 0에 가깝게 나온다. Dimension에 비례하여 dot product의 스케일을 줄이면 이러한 현상을 완화할 수 있다고 한다.
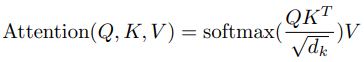
\(QK^TV\)의 차원은 \((L_{in},d_k) \times (d_k,L_{in}) \times (L_{in},d_v) = (L_{in},d_v)\) 이다. Self-attention 식의 \(Q,K,V\)는 사실 Multi-head attention 식의 \(QW^Q, KW^K, VW^V\) 이다. 논문에서는 self-attention 식을 먼저 설명해서 편의상 새로운 기호를 쓰지 않고 \(Q,K,V\)를 쓴 것 같다.
Self-attention의 의미는 무엇일까? 첫 번째 dot product \(QK^T\) 에서 \((L_{in},L_{in})\)의 행렬이 나오는데 무슨 의미일까? \(QK^T\)의 (i,k) 원소의 의미는 i번째 query와 k번째 key 사의의 연관성이라고 볼 수 있다. “GNU is Not Unix” 예시에서 (0, 2) 원소는 ‘GNU’와 ‘Not’ 사이의 연관성이다. 이 연관성을 합이 1이 되도록 normalize 하기위해 softmax를 한다.
단어 사이의 연관성을 계산한 후 Value를 곱하면 \(QK^TV\)의 i번째 행(row)는 i번째 단어에 대한 새로운 임베딩이 된다. 이것은 i번째 단어의 정보 뿐만 아니라, i번째 단어와의 연관성에 따라 모든 단어의 linear combination이기 때문에 전체 문맥에서 가지는 i번째 단어의 의미 같은 것을 알 수 있게 된다. 이점이 RNN과의 가장 큰 차이점이다. 순서대로 입력하지 않고 처음부터 전체를 다 보기 때문에 sequence가 길어져도 멀리 떨어진 단어들 사이의 관계를 파악할 수 있다. 언어 사이의 어순이 달라도 이를 처리할 수 있다.
A.4. Multi-head attention
Multi-head attention에서는 self-attention을 여러개 사용하는데 이건 마치 CNN의 convolution에서 채널 마다 다른 특징을 추출하는 것과 비슷한 것 같다. Self-attention도 하나만 있으면 정확한 문맥 파악을 잘 못 할수 있지만 여러가지 self-attention을 쓰면 다양한 문맥적 의미를 탐색하여 최종적으로는 더욱 정확한 의미를 알 수 있다.
Multi-head attention에서는 \(d_v\) 차원의 출력이 \(h\)개 나온다. 최종 출력은 입력과 같은 \(d_{model}\) 이 되어야 하기 때문에 Multi-head의 결과물들을 concat하여 \(h * d_v\) 차원의 행렬을 만들고 여기에 \(W^O (h*d_v,d_{model})\)을 곱하여 \(d_{model}\) 차원의 벡터를 출력한다.
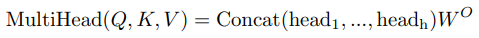
A.5. Feed forward
Multi-head attention 이후 Add&Norm 레이어가 있다. ResNet 처럼 입력을 출력에 더해주는데 이것은 벡터(단어의 임베딩)의 순서 정보를 잊지 않기 위함이다. Layer Normalization 까지 적용후 feed forward net(FFN)을 통과하는데 이것은 단순히 Linear-ReLU-Linear 조합이다.
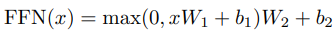
FFN은 벡터(단어)별로 따로 적용된다. 같은 레이어에서 벡터 별 적용되는 \(W_1, W_2\)는 같지만 레이어 별로 다른 weight를 가진다. 이후 한 번 더 Add&Norm 레이어를 통해 입력과 출력을 더하고 정규화한다.
A.6. Stack
인코더는 self-attention과 FFN이 결합된 하나의 인코더 레이어를 6번 쌓아 만든다. 인코더의 최종 출력만 디코더에 입력으로 들어간다. 인코더는 auto-regressive 하지 않기 때문에 출력이 입력으로 다시 들어가지 않고 병렬로 모든 입력 데이터를 처리한다.
C. Decoder
디코더도 인코더와 비슷한데 세 가지 차이가 있다.
C.1. Input
인코더와 달리 디코더는 auto-regressive 하다. 이전의 출력이 현재의 입력으로 들어간다. 디코더의 첫 입력은 SoS (Start of Sentence)이고 이후 출력이 하나씩 붙어서 점점 입력 단어 수가 늘어난다. 계속 출력이 입력에 추가되다가 EoS (End of Sentence) 가 출력되면 중단된다.
C.2. First multi-head attention
디코더에서는 multi-head attention이 두 개 들어간다. 첫 번째는 Masked mutli-head attention 인데 ‘mask’는 “Scaled Dot-Product Attention” 그림에서 “Mask (opt.)”라고 된 블럭을 말한다. 디코더의 첫 번째 multi-head attention에서만 이 masking이 적용된다.
논문에서는 auto-regressive한 성질을 유지하기 위해, 즉 미래의 입력을 사용하는 “leftward information”을 막기 위해, softmax 전에 미래 입력에 대한 값들을 \(-\infty\)로 바꿔서 softmax에서 0이 나오도록 했다.
여기서 의문이었던 점은 원래 입력에 과거부터 현재까지의 단어만 들어오는데 masking 해야 할 미래의 입력이 무엇인지 이해할 수 없었다. 하지만 코드를 보니 학습할 때는 target sentence (GT output)을 디코더에 바로 넣어서 한번에 문장이 나오도록 했다. 즉 “<SoS> 그누는 유닉스가 아니다”를 바로 디코더에 입력해서 “그누는 리눅스가 아니다 <EoS>“가 나오도록 학습하는 것 같다. 그래서 각 단어별로 그 다음 단어에 대한 입력을 masking 하게 한 것이다. 예를 들면 ‘그누’라는 단어를 처리 할 때는 ‘유닉스가’, ‘아니다’를 masking 하는 것이다.
C.3. Second multi-head attention
두 번째 multi-head attention은 입력 구성이 다르다. 기존에는 하나의 입력이 세 갈래로 갈라지면서 Query, Key, Value가 됐다. 여기서는 인코더의 최종 출력이 Value, Key로 들어오고 첫 번째 attention의 출력은 Query로만 들어간다.
다음 레이어로 넘어가는 Value(단어 임베딩?)은 인코더에서 가져오고 인코더의 Key와 디코더의 Query를 dot product 한다. 인코더는 입력 언어(영어)에 대한 정보를 담고 있고 디코더는 새로운 언어(한글)에 대한 정보를 담고 있다. 디코더의 Query를 이용해 인코더의 Value 중에서 이번에 출력될 다음 단어(한글)와 관련된 입력 언어(영어)의 단어 정보를 조합하는 것이다.
D. Final Output
논문에서도 유툽, 블로그 등에서도 간단히 최종 출력은 Linear - Softmax로 다음 단어가 하나 나오고 끝나는 듯 말하지만 세부적인 내용을 숨기고 있다.
인코더에서는 입력과 출력의 dimension이 똑같다고 했다. 즉 입력 단어가 5개면 출력되는 임베딩도 5개다. 디코더도 거의 비슷한 구조인데 auto-regressive하게 출력을 내면 출력되는 임베딩의 개수가 늘어날 수 밖에 없다. 처음엔 1개, 다음엔 2개 이런식으로 디코더 자체의 출력 임베딩 수가 늘어나게 된다. 출력 데이터의 차원이 일정하지 않은데 어떻게 Linear 레이어를 적용할까?
번역하는 코드를 보니 for문을 돌면서 auto-regressive 하게 하는 것 같지만 _get_the_best_score_and_idx 이 함수가 끝내 잘 이해되진 않았다. 대략 추측하기로는 마지막 Linear - Softmax 레이어도 출력 임베딩 별로 따로 적용하고 그 결과로 나온 단어 별 벡터들을 스텝별로 쌓아두고 그 중에서 가장 좋은 (score가 높은?) 벡터를 선택하는 것 같다. 즉 단어를 순서대로 입력하면 ‘그누는’이라는 단어가 디코더에 세 번 들어가는데 그 결과로 나온 세 개의 벡터 중에 가장 좋은 것을 선택하는 것 같다.
1.2. Loss
딥러닝 논문이라면 자로고 Loss를 잘 설명해야 하거늘 이 논문에는 loss라는 단어가 아예 없다!
결과가 softmax로 나오므로 당연히 cross entropy loss를 쓸거라고 생각은 하지만… Loss와 관련된 내용은 label smoothing을 쓴다는 것 뿐이다.
2. DETR
| Title | End-to-End Object Detection with Transformers |
|---|---|
| Authors | Nicolas Carion 외 6명 (모두 Facebook AI) |
| Publisher | ECCV, 2020 |
| github | https://github.com/facebookresearch/detr |
DETR 모델은 Transformer를 detection에 응용한 첫 논문이다. Transformer가 단순히 시계열 데이터 뿐만 아니라 영상에도 사용될 수 있음을 보여줬다. Detection에 Transformer를 사용하여 생기는 장점으로는 anchor 기반 box decoding이나 NMS (Non-Maxiumum Suppression) 같은 후처리 없이 바로 객체(class + bounding box)를 출력한다는 것이다. DETR은 정해진 \(N\)개의 객체를 출력하고 그 중에서 객체가 아닌 것들은 no object로 처리되어 실질적인 출력 객체 수를 조절할 수 있다.
2.1. Model Architecture
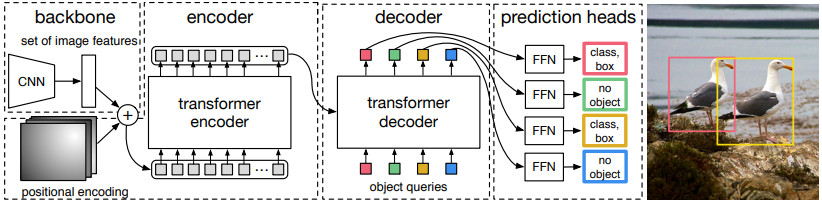
A. Backbone
이미지를 특징 벡터로 만들기 위해 CNN을 사용한다.
-
입력: image, \(x_{img} \ (3, H_0, W_0)\), 파이토치에서는 channel-first dimension 사용
-
출력: feature map, \(f \ (C, H, W), \ C=2048, \ H=H_0/32, \ W=W_0/32\),
B. Encoder
feature map의 dimension이 너무 크기 때문에 1x1 convolution을 통해 채널을 \(d\)개로 줄인다. 이후 데이터 변형을 거쳐 \(HW\) 개의 \(d\) 차원 벡터를 인코더에 입력하여 같은 모양의 출력(임베딩)을 얻는다. 여기서는 feature map의 각 픽셀 데이터들이 sequence를 이루는 셈이다.
- conv: \(f \rightarrow z_0 \ (d,H,W), \ d \ll C\)
- reshape: \(z_0 \rightarrow z_1 \ (d, HW)\)
- permute: \(z_1 \rightarrow z \ (HW, d)\)
- encoder: \(z \rightarrow g \ (HW, d)\)
실제 구현에서는 batch size까지 들어가서 2, 3이 다음과 같이 구현된다.
h: \((B,d,H,W)\)h.flatten(2): \((B,d,HW)\)h.flatten(2).permute(2,0,1): \((HW,B,d)\)
인코더 구조 자체는 순서와 상관없기 때문에 (permutation-invariant) 순서를 알려주기 위한 positional encoding을 인코더 입력 직전에 더해준다. 자세한 구조는 아래 그림에 나와있다.
C. Decoder
DETR의 디코더는 Attention Is All You Need 와는 다르게 auto-regressive 하지 않다. N개의 query를 처음에 한번에 입력해서 N개의 출력을 한번에 얻고 끝낸다. 코드에서 확인한 바로는 그림의 “Object queries”는 단순히 모양만 맞춘 zeros 행렬이다. 처음에는 zeros지만 attention 레이어에 들어가기전에 positional encoding이 더해지기 때문에 query 별로 다른 값을 가질 수 있다. 두 번째 디코더에서부터는 이전의 디코더 출력이 다음 디코더의 입력이 되므로 점점 의미를 더해갈 수 있다.
D. FFN
디코더 이후에 실제 detection 결과를 내기 위해 feed-forward network (FFN)을 통과한다. 최종 출력은 클래스와 박스 정보다. 클래스 예측을 위해 linear 레이어 하나를 쓰고 여기에 softmax를 적용하면 클래스 확률이 된다. 클래스에는 no obect가 포함된다.
박스 예측을 위해 linear-relu-linear-relu-linear 구조를 가진 FFN을 사용하고 여기에 sigmoid를 적용하면 박스의 (y,x,height,width)를 이미지에 대한 비율로 출력할 수 있다.
2.2. Loss
A. Bipartite Matching
Loss를 계산하기 위해서는 우선 모델의 prediction set과 GT set을 매칭을 시켜야한다. DETR에서는 prediction과 GT를 1:1 매칭을 하는데 이를 bipartite matching이라고 표현한다. 매칭 방법은 Hungarian algorithm을 쓴다고 하는데 구현 방법은 모르겠지만 모든 매칭에 대한 손실의 합을 최소화하는 매칭 쌍을 찾는다고 한다. 각 GT 객체와 매칭되는 prediction 객체는 아래 식으로 구한다.
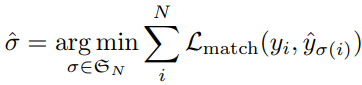
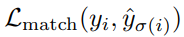 =
= 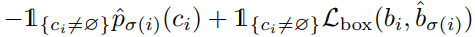
- \(y, \ \hat{y}\) : GT and prediction object
- \(\sigma(i)\) : i번째 GT에 매칭되는 prediction index
- \(b, \ \hat{b}\) : GT and prediction bounding box
- \(c_i\) : GT class index
- \(\hat{p}_{\sigma(i)}(c_i)\) : \(\sigma(i)\) 번째 prediction 객체에서 출력된 \(c_i\) 번째 클래스의 확률
매칭 Loss의 의미는 “매칭 쌍 사이의 box loss는 작아야하고 정답 클래스의 확률은 높아야 한다”는 것이다. 모든 매칭 쌍에 대해 매칭 loss의 합이 최소가 되는 1:1 매칭을 찾겠다는 것이다. GT와 매칭되는 prediction이 없으면 no object로 매칭이 된다.
B. Training Loss
학습에 사용되는 loss는 클래스를 위한 cross-entropy loss와 box loss의 합이다. Box loss는 GIoU loss와 L1 loss의 조합이다.
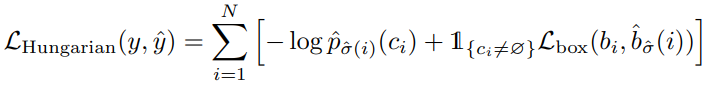
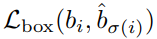 =
= 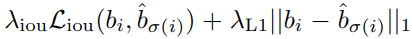
3. Deformable DETR
| Title | DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION |
|---|---|
| Authors | Xizhou Zhu 외 5명 (주로 SenseTime Research) |
| Publisher | ICLR, 2021 |
| github | https://github.com/fundamentalvision/Deformable-DETR |
Deformable DETR은 기존 DETR의 두 가지 문제를 deformable attention module로 해결하였다.
- 느린 수렴 속도: 500 epoch은 학습시켜야함 → 10배 감소
- 많은 연산량, 메모리 필요: 픽셀 수 제곱 비례 → 선형 비례
3.1. Deformable Attention Module
기존 DETR의 문제는 encoder의 연산량에 있다. 이미지에서 \(HW\)개의 feature vector들이 만들어지고 이게 모두 Query, Key, Value로서 들어간다. 모양이 \(Q (HW,C), \ K(HW, C)\) 이므로 \(QK^{T}\)만 해도 연산량이 \(O(H^2W^2C)\)가 된다. 연산량이 픽셀 수에 제곱에 비례하므로 고해상도 이미지, 혹은 feature map을 처리할 수 없고 따라서 작은 객체를 잡기가 어려워진다. CNN 기반 detector들이 multi-scale feature map을 써서 다양한 크기의 객체들을 검출하는데 DETR은 연산 시간이나 메모리의 벽에 막혀 고해상도 feature map을 처리할 수 없게 된다.
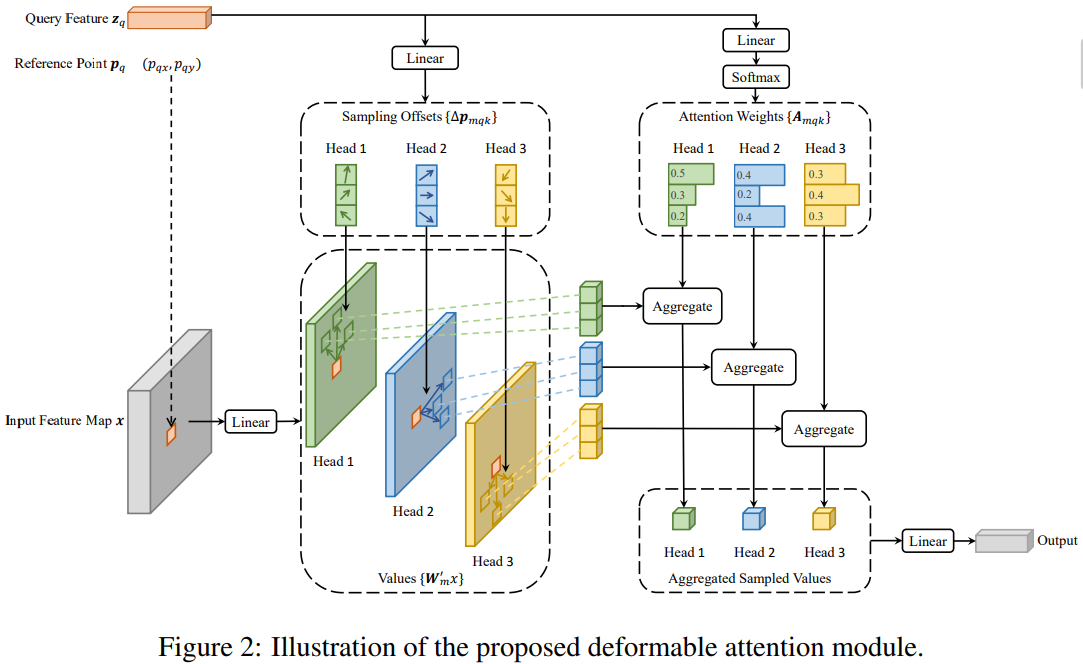
Deformable attention은 Key, Value의 개수를 줄였다. 위 그림은 query feature vector 하나 \(\mathbf{z}_q\)를 처리하는 과정이다. \(\mathbf{z}_q\)의 feature map 좌표가 reference point \(\mathbf{p}_q\) 이다.
\(\mathbf{p}_q\)에 어떤 객체가 있냐? 라는 query에 대답하기 위해 head에서는 \(\mathbf{p}_q\) 근처의 점들을 \(K_0\)개 샘플링하여 key, value로 사용한다. (그림에서 \(K_0=3\)) 당연히 그래야 할 것 같지만 DETR에서는 \(\mathbf{p}_q\)에 있는 객체를 찾기 위해 모든 픽셀의 정보를 취합했다. Deformable attention에서는 \(QK^{T}\)의 연산량이 \(O(HWK_0C)\) 이 된다. \(K_0 \ll HW\)이므로 DETR의 \(O(H^2W^2C)\) 보다는 훨씬 줄어드는 것이다.
단순히 연산량이 줄어든 것 뿐만 아니라 attetion의 방식 자체가 달라졌다. \(K_0\)개의 샘플들은 그림의 “Sampling Offsets” 박스에 나온대로 query에 linear 레이어를 적용하여 reference point에 대한 상대 좌표를 만들어낸다. 이 linear 레이어도 학습이 되므로 검출에 유리한 주변 점들의 위치를 학습하게 된다.
DETR의 attention 방식은 모든 픽셀에 일단 attention을 골고루 뿌려놓고 학습을 통해서 서서히 attention이 특정 픽셀들로 집중된다. 그래서 학습이 오래 걸린다.
Deformable DETR은 query와 관련된 픽셀을 상대적으로 적은 개수로 정해놓고 관련 픽셀의 위치를 학습하기 때문에 학습이 빠르게 진행될 수 있다.
3.2. Deformable Transformer
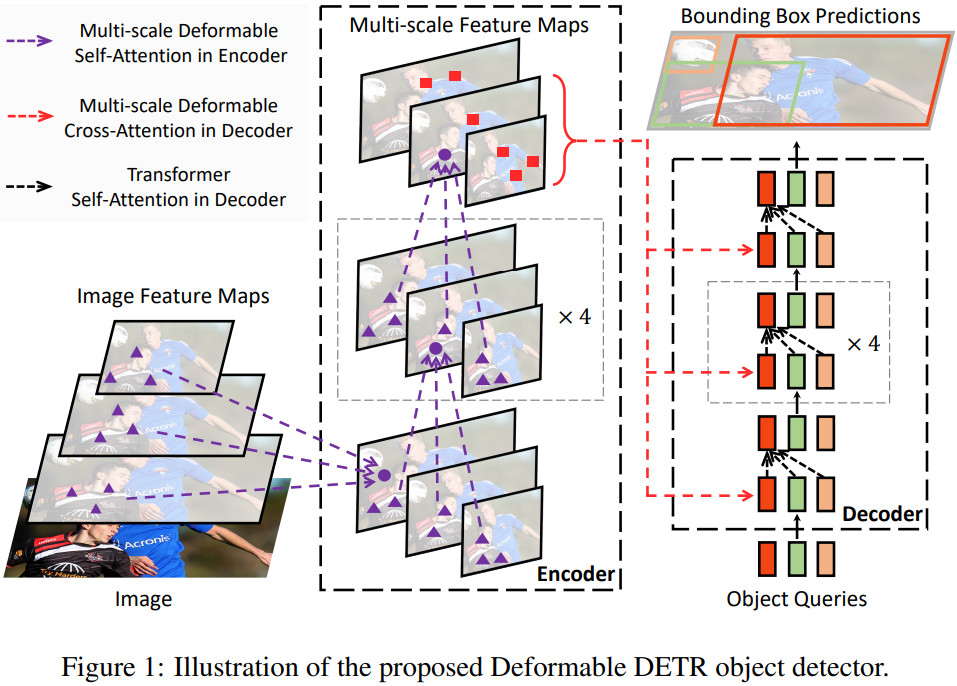
Deformable Transformer의 전체적인 모습은 위 그림과 같다. 기존 DETR에서 attention 모듈을 deformable attention로 바꾼것이다. 인코더의 self-attention과 디코더의 cross-attention은 deformable로 바꿨고 디코더의 self-attention은 기존 그대로 사용했다.
3.3. Additional Improvements
A. Iterative Bounding Box Refinement
Bounding box의 정확도를 높이기 위해 첫 디코더 레이어에서 box 출력을 하고 다음 레이어에서는 이전 레이어에서 출력된 box를 보정하는 것을 반복한다.
B. Two-Stage Deformable DETR
인코더를 RPN(region proposal network)으로 쓰고 거기서 나온 proposal을 디코더의 object queries로 사용한다. 그런데 정확히 어떻게 인코더를 RPN으로 쓰는지는 모르겠다.
4. Vision Transformer (ViT)
| Title | AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE |
|---|---|
| Authors | Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, 외 8명 (Google Research) |
| Publisher | ICLR, 2021 |
| github | https://github.com/google-research/vision_transformer |
ViT는 DETR과는 다르게 아예 CNN을 쓰지 않고 순수하게 Transformer 원형을 그대로 사용하여 영상 분류에 적용한 연구다. 일반적인 학습 방법으로는 Transformer가 기존의 CNN보다 좋은 성능을 내진 못 한다. Transformer에는 CNN과 다르게 inductive bias가 없기 때문이다. 여기서 inductive bias란 모델 구조에 내재되어있는 입력 데이터에 대한 사전 정보를 의미한다.
CNN은 영상의 채널을 가지는 2차원적 구조를 제대로 활용한 모델이다. 모든 위치에서 동일한 local 필터를 적용하기 때문에 의미 있는 객체가 어디에 있든 상관없이 찾을 수 있다.
하지만 transformer는 들어오는 모든 정보들 사이의 관계성을 추론하기 때문에 공간상으로 가까운 픽셀들 사이에 더 밀접한 관계가 있다는 것조차 학습해야 한다. 따라서 Transformer를 제대로 학습하기 위해서는 기존의 BERT나 GPT에서 하듯 초대량의 데이터로 사전 학습을 시킨 후 특정 task를 위한 fine-tuning을 해야 한다. 이 논문에서도 ImageNet 분류 문제에서 좋은 성능을 내기 위해 이보다 훨씬 큰 분류 데이터셋을 활용해 사전학습을 시켰다. 그랬더니 영상의 공간적인 구조까지 학습하게 되어 CNN보다 더 높은 분류 성능을 냈다는 결론이다. 이제 자세히 알아보자.
4.1. Model Architecture
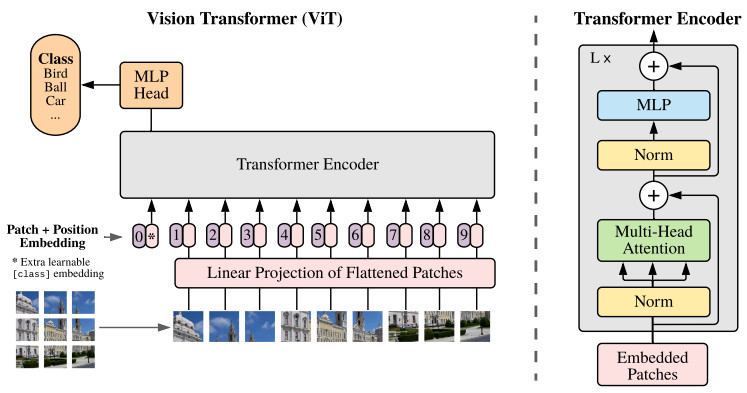
A. Split into Patches
Transformer를 영상에 적용할 때 가장 큰 문제는 영상을 Encoder에 입력하는 방법이다. Naive한 방식으로는 이미지를 1차원으로 펴서 픽셀을 하나씩 넣는 것이지만 (\(N=HW\)) 이는 transformer에서 입력 개수의 제곱에 비례하는 메모리와 연산이 들어가므로 극히 비효율적이다. DETR에서는 CNN backbone을 거쳐 feature map을 만들면 자연스럽게 해상도가 줄어들므로 이를 조금 완화했고 Deformable DETR에서는 attention의 범위를 고정된 크기로 줄여서 효율성을 크게 높였다.
ViT에서는 inductive bias를 최대한 배제하기 위해 이미지를 \(P \times P\) 크기의 패치들로 쪼갠 뒤 각각의 패치를 1차원으로 펴서 linear projection을 시켜 일정 차원의 입력을 만든다. 패치의 해상도가 \(P \times P\)이면 영상은 \(N=HW/P^2\) 개의 패치로 나뉘게 된다. (논문 제목은 마치 패치 수가 \(P \times P\) 인것 같지만 이것은 각 패치의 해상도를 나타낸다.) 각각의 패치는 1차원으로 flatten 한 뒤 linear layer에 입력하여 \(D\)차원의 Input Embedding을 만든다. 논문에서 사용한 패치 크기는 \(P = 16\) 이다.
- \(\mathbf{x} \ \ (H,W,C)\) : input image
- \(\mathbf{x}_p \ \ (N, P^2C)\) : image patches
- \(\mathbf{z}^i = \mathbf{x}_p^i \mathbf{E} \ \ (P^2C) \times (P^2C,D) = (D)\) : linear projection
B. Position Embedding
영상이지만 Position embedding은 1차원적으로 생성한다. 그림에서 패치들을 일렬로 세워놓은 순서대로 Position Embedding을 생성하여 앞서 만든 Input Embedding에 더해서 Encoder에 입력한다. Position Embedding도 당연히 \(D\) 차원 벡터다.
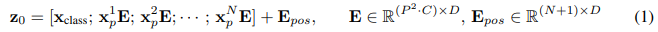
C. Class Token
Encoder의 맨 앞에 들어가는 embedding은 모델에서 수행할 작업을 나타내는 [class] 토큰이다. (만약 이 모델에서 classification외에 다른 작업을 동시에 학습한다면 그와 관련된 입력 토큰과 Head를 추가하면 된다.) [class] 토큰은 학습가능한 파라미터다. [class] 토큰에 해당하는 출력이 그림 속 “MLP Head”에 들어간다.
D. Transformer
ViT의 Transformer는 “Attention Is All You Need”에서 처음 발표된 Encoder 구조와 같다. 다음 수식으로 요약 가능하다.
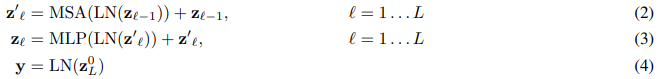
E. Head
MLP Head는 단순히 Linear 레이어 하나로 구성되어있다. Encoder의 입력은 \((N+1)\)개의 벡터 이므로 출력도 \((N+1)\)개의 벡터가 나온다. 이 벡터들이 모두 Head에 들어가지 않고 앞서 말했다시피 [class] 토큰에 해당하는 첫 번째 출력(그림에서 가장 왼쪽)만 Head에 들어간다.
Transformer는 global attention을 제공하므로 (영상 전체를 볼 수 있으므로) 이 [class] 토큰과 모든 영상 패치에서 나오는 embedding들이 섞여서 각 단계의 encoder 출력으로 나온다.
4.2. Training
A. Pretraining
Transformer는 영상의 2차원적, 국소적 특성에 대한 이해가 전혀 없으므로 대량의 데이터셋으로 사전 학습을 시켜야 좋은 성능을 낼 수 있다. ImageNet에서 좋은 성능을 내기 위해 ImageNet-21k나 JFT처럼 훨씬 더 큰 규모의 데이터셋으로 사전 학습을 시켰다.
- Target task: “ImageNet” (ILSVRC-2012 ImageNet with 1k classes and 1.3M images)
- Pretraining: “ImageNet-21k” (21k classes and 14M images), “JFT” (18k classes and 303M images)
B. Training Downstream Task
사전 학습을 시킨 후에는 MLP Head를 제거하고 ImageNet으로 fine-tuning을 한다. 이렇게 사전학습된 모델을 작은 데이터셋에 적용하는 것을 Downstream Task라고 한다.
Fine-tuning을 할 때 사전학습 보다 더 고해상도 이미지로 학습하면 더 좋은 결과를 낼 수 있다고 한다. 그런데 여기서 해상도를 늘리면 패치의 개수가 늘어나게 된다. 늘어난 패치를 Transformer에 입력하는 것은 문제가 없으나 position encoding이 달라져야 하는 것이 문제다. 여기서는 사전학습에서 사용한 position encoding를 2차원 공간에서 bilinear interpolation해서 사용했다고 한다.
4.3. Results
Table 1은 모델의 규모인데 파라미터 규모가 대략 억단위다. 참고로 EfficientNet 모델들이 대략 천만 단위의 파라미터 수를 가진다.
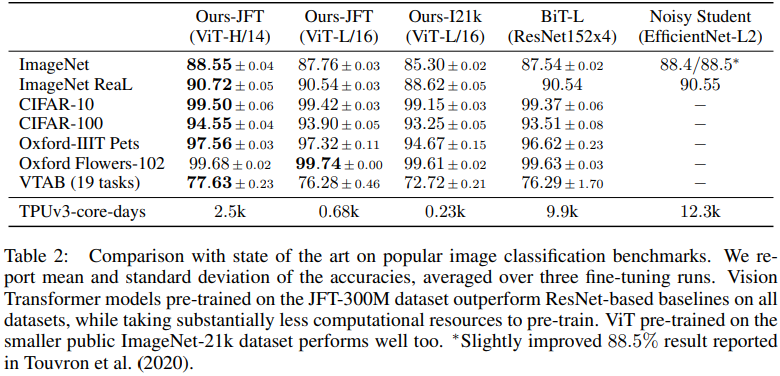
Table 2는 CNN기반 모델(BiT-L, Noisy Student)과 비교해서 더 나은 결과를 냈다는 것을 보여준다.
5. Data efficient image Transformers (DeiT)
| Title | Training data-efficient image transformers & distillation through attention |
|---|---|
| Authors | Hugo Touvron, Matthieu Cord 외 4명 (Facebook AI & Sorbonne University) |
| Publisher | ICML, 2021 |
| github | https://github.com/facebookresearch/deit |
ViT가 transformer 구조를 이용해 기존 CNN을 뛰어넘는 성능을 보여주긴 했지만 사전학습을 위해 어마어마한 양의 데이터와 연산자원이 필요했다. ViT와 거의 같은 구조를 가지면서 부담스러운 사전학습 없이 ImageNet에서 SOTA를 찍은 논문이다. 모델 구조는 ViT와 거의 유사한데 학습 방식을 개선하여 성능을 끌어올렸다.
핵심 개념은 Knowledge distillation 이다. (지식 증류?) Distillation에서는 대개 규모가 큰 고성능의 teacher 모델과 상대적으로 작은 student 모델이 있어서 teacher의 출력을 student가 따라하도록 학습시키는 방식이다. 잘 되면 student를 직접 GT label을 가지고 학습시키는 것보다 나은 성능을 낼 수 있다. Student가 teacher에 가까운 성능을 낸다면 이를 모델 압축 기술로도 볼 수 있다. 이것의 장점 중 하나는 mislabel을 스스로 수정하여 학습할 수 있다는 것이다. 라벨이 처음부터 잘못 들어갈수도 있고 data augmentation 과정에서 GT label의 객체가 사라질수도 있다. 그럴때 teacher 모델이 올바른 label을 알려주면 학습이 더 잘 될수도 있다.
DeiT는 ViT 모델에 Distillation 기법을 적용했더니 적은 학습 데이터로도 transformer가 학습이 잘 됐다는 내용이다.
5.1. Model Architecture
모델 구조는 ViT와 거의 비슷하다. 입력 이미지를 \(16 \times 16\) 크기의 패치들로 잘라서 linear projection한 결과를 patch token으로 입력하고 클래스를 출력하기 위해 학습 가능한 class token도 입력한다.
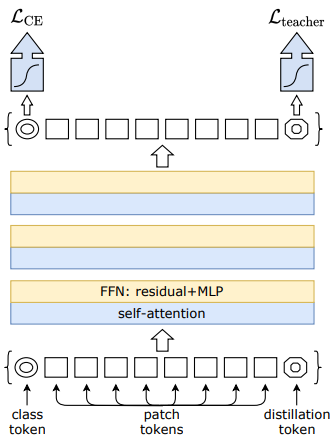
차이는 distillation token이 있고 이로부터 만들어진 출력을 teacher 모델로부터 학습시키는 용도로 쓴다는 것이다. class token의 출력은 GT label로 학습하고 distillation token의 출력은 teacher label로 학습한다. GT label로 학습할 때는 label smoothing 기법을 적용한다. Distillation을 할 때 teacher의 출력을 그대로 따라하는 soft distillation이 있고 분류 결과만을 학습하는 hard-label distillation이 있는데 hard-label의 성능이 더 좋다고 한다. Distillation에서는 label smoothing을 적용하지 않는다.
5.2. Results
DeiT에서는 다른 대량의 데이터셋으로 사전 학습을 하지 않고 타겟 데이터셋으로 직접 학습한다. 논문 첫 페이지에 나온 실험 결과는 아래와 같다. ImageNet Top-1 accuracy인데 갈색선은 Distillation을 적용하지 않은 것(ViT와 동일), 황색선은 EfficientNet, 옆에 증류 기호(?)가 붙은 빨간선은 Distillation을 적용한 모델이다. 가로축은 Throughput(초당 처리 이미지 수)이고, 세로축은 정확도니 오른쪽 위로 올라갈 수록 좋다. CNN 대표선수인 EfficientNet과 비교해보면 비슷한 throughput을 가진 모델 대비 정확도가 더 높게 나오는걸 볼 수 있다.
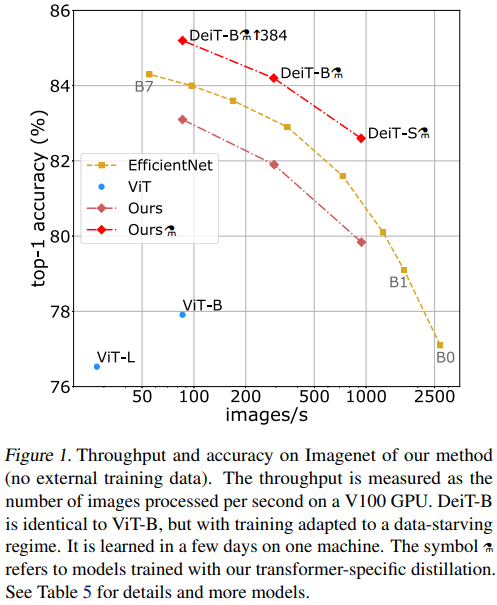
표 3은 Distillation의 효과를 보여준다. 위에서부터 6개 모델은 다음과 같다.
- no distillation: 그냥 ViT처럼 학습한 것
- usual distillation: GT label 없이 teacher 모델로 soft distilation 한 것
- hard distillation: GT label 없이 teacher 모델로 hard-label distilation 한 것 (여기까지 head는 하나)
- class embedding: Distillation 적용하고 class embedding 에서 나온 출력 평가
- distill. embedding: Distillation 적용하고 distil. embedding 에서 나온 출력 평가
- DeiT: class+distil.: Distillation 적용하고 두 가지 embedding에서 나온 출력을 결합한 결과
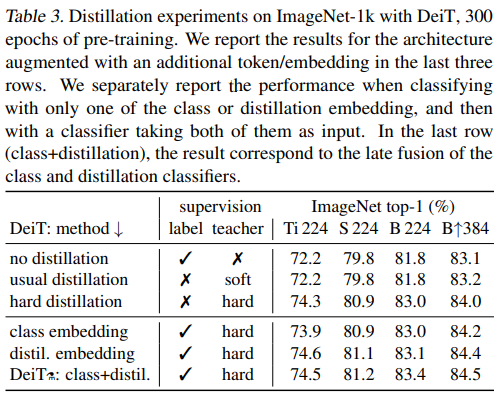
표 3을 보면 2번에서 3번으로 넘어갈 때 가장 큰 성능 개선이 있다. GT label보다 teacher label이 더 학습에 효과적이라는 것이다.
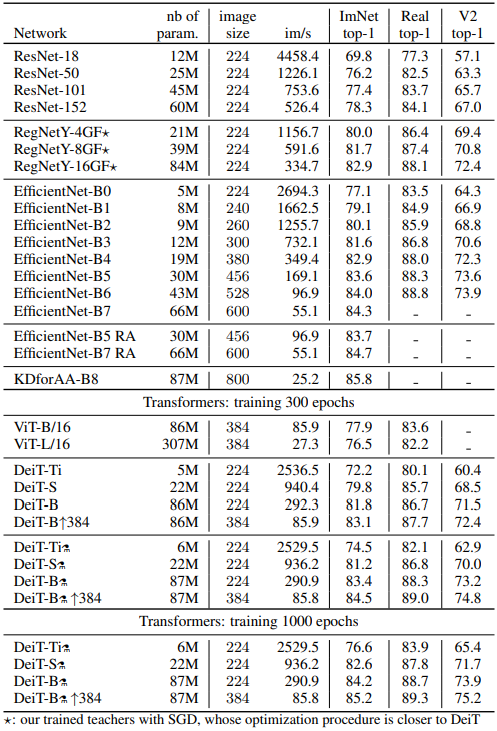
아래는 표 5번인데 여러 모델의 성능을 ImageNet, Real ImageNet, ImageNet V2 데이터셋으로 비교했다. EfficientNet과 비교했을때 파라미터 수는 조금 더 많지만 파라미터 수에 비해서는 빠르게 동작한다.
6. Swin Transformer
| Title | Swin Transformer: Hierarchical Vision Transformer using Shifted Windows |
|---|---|
| Authors | Ze Liu, Yutong Lin, Yue Cao, Han Hu 외 4명 (Microsoft Reasearch Asia(MSRA)) |
| Publisher | ICCV, 2021 |
| github | https://github.com/microsoft/Swin-Transformer |
드디어 Swin Transformer까지 왔다. DETR은 CNN backbone을 쓴다는 찜찜함(?)이 남아있고 ViT나 DeiT는 classification만 되는 모델이라서 아쉬움이 남았다. Compution Vision 분야에서 아직도 가장 중요한 분야인 Detection이나 Segmentation에 Transformer만을 이용하여 SOTA 성능을 낸 게 바로 Swin-Transformer다. 최신 논문들의 성능은 이곳에서 비교해 볼 수 있다. COCO leadearboard는 최신 내용이 반영되지 않는것 같다.
- Detection (COCO) : https://paperswithcode.com/sota/object-detection-on-coco
- Segmentation (ADE20K) : https://paperswithcode.com/sota/semantic-segmentation-on-ade20k-val
상위권 모델의 이름이나 설명에 Swin이라는 단어가 자주 눈에 띈다. 지금 소개할 Swin Transformer를 기반으로 만들었다는 뜻이다. Swin Transformer에서는 Transformer를 CNN처럼 feature map을 만드는 backbone으로 사용할 수 있게 했다. 이후 이 feature map을 이용하여 classification / detection /segmentation 등을 할 수 있는 것이다. 자세한 내용을 알아보자.
5.1. Model Architecture
Swin Transformer(이하 Swin-T)의 가장 큰 혁신은 Transformer를 Window 별로 따로 적용하고 그걸 계층화하여 단계적으로 통합한 것이다. Transformer를 CNN처럼 피라미드 구조로 만들었다. Figure 1을 보면 모델 구조를 ViT와 비교하였다.
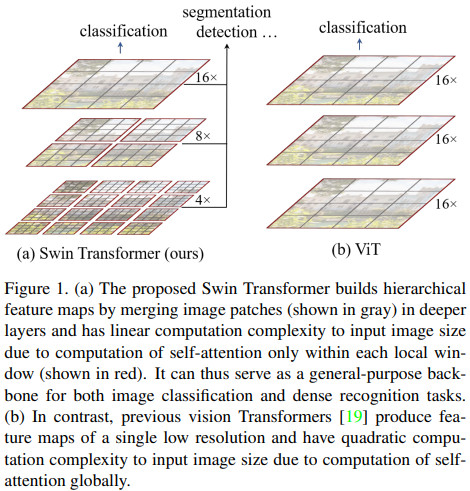
ViT의 문제점은 이미지 해상도에 제곱에 비례하는 연산량이다. 이미지 전체에 대해 attention을 계산하기 때문에 이미지 해상도가 \(H \times W\) 이고 패치 크기가 \(16 \times 16\)이면 Transformer에 입력되는 패치의 개수는 \(N = H/16 \times W/16\) 이 되고 attention 계산에는 \(N^2\)에 비례하는 연산량이 필요하게 된다. ViT는 classification만 하기 때문에 해상도를 그렇게 높일 필요가 없지만 dense prediction이 필요한 detection / segmentation의 경우에는 고해상도의 이미지를 처리할 경우가 많은데 ViT로는 답이 없게 된다.
그래서 Swin-T에서는 이미지 패치들을 하나의 Transformer에 한 번에 넣지 않고 window 별로 나눠서 처리한다. Window 크기가 정해지면 window 내부에서의 transformer 처리량은 동일하다. 이미지 해상도에 따라 달라지는 것은 window의 개수뿐이고 그것은 이미지 해상도(픽셀 수)에 비례한다. 그래서 Swin-T의 연산량은 이미지 해상도에 비례하고 이는 고해상도의 이미지를 처리하기가 수월해진다는 뜻이다.
이미지를 window 별로만 처리하면 전체적인 영상을 볼 수 없으므로 CNN 처럼 단계적으로 feature map 크기를 반씩 줄여나간다. 이렇게 하면 이미지 해상도 대비 1/4, 1/8, 1/16 크기의 feature map이 나오게 되고 여기에 detection head나 segmentation head를 붙이면 된다.
상세한 모델 구조는 Figure 3에 나와있다.
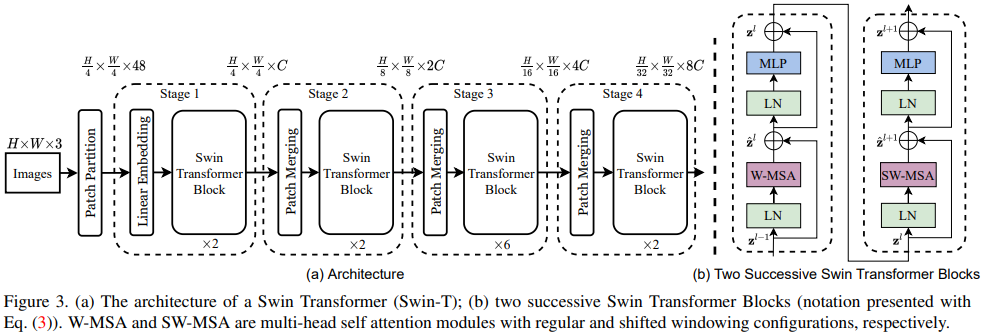
- Patch Partition: 이미지를 \(4 \times 4\) 크기의 패치들로 분할한다.
- Linear Embedding: Linear 레이어를 통해 feature 생성
- Swin Transformer Block: Window 별로 따로 transformer 를 적용한다.
- Patch Merging: 입력된 feature map의 해상도를 1/2로 줄인다. Feature map에서 \(2 \times 2\) 픽셀씩 묶어 4개의 feature vector를 하나로 concat하고 (4C) linear 레이어를 통해 채널을 반으로(2C) 줄인다. 결과적으로 채널 수가 2배로 늘어난다.
6.2. Shifted Window
Windowed attention은 window끼리 영역이 겹치지 않기 때문에 효율적이긴 하지만 window 사이의 경계면에서의 정보가 부족하다는 단점이 있다. 이를 보완하기 위해 window 분할 영역을 Figure 2처럼 움직여서 (shifted window) 원래(왼쪽)의 window와는 다른 픽셀들과의 attention을 계산할 수 있게 했다. Figure 3 (b)처럼 Swin-T에서는 두 가지 분할 방식을 번갈아가며 사용한다. W-MSA가 정상적인 window 분할 상태에서의 multi-head self attention (MSA)이고 SW-MSA는 shifted window 상태에서 MSA를 적용한 것이다.
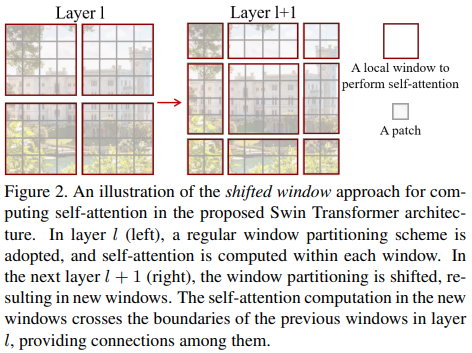
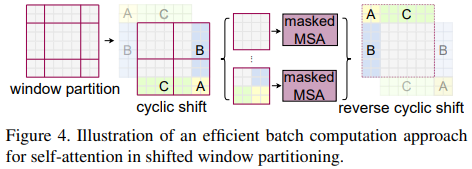
하지만 Figure 2의 오른쪽 그림처럼 분할시 window가 4개에서 9개가 되고 window 크기도 일정하지 않다는 단점이 있다. 그래서 가장 자리에 남은 자투리(?) window들을 모아서 원래 크기의 window를 만들면 기본 window 분할처럼 똑같은 크기의 4개의 window로써 처리할 수 있다.
Swin-T는 CNN backbone을 대체해서 쓸 수 있기 때문에 이 위에 FPN, PANet 등을 붙이면 detection / segmentation 예측을 출력할 수 있다. 이 논문에서 비교대상이 된 ViT 입장에서 보면 Swin-T는 영상에 대해 너무 많은 inductive bias를 가지고 있다. 사실상 CNN 구조에서 convolution 대신 attention mechanism을 넣은 것과 같다. 이미지의 2차원 적이고 계층적인 구조를 활용한 것이다. 하지만 논문은 역시 성능이 잘 나오는게 중요하다.
7. Why Transformer for Computer Vision?
여기까지 정리하면서 느낀 점은 transformer 구조가 장점이 많고 computer vision에도 잘 어울린다는 것이다. 처음 Attention is All You Need 를 읽었을 때 들었던 여러가지 의구심들이 해소되었다.
이게 왜 좋을까?
Transformer는 기존의 MLP, LSTM, CNN 보다 뭐가 나을까?
Transformer는 기본적으로 MLP에 기반한다. MLP는 원래 입력 데이터의 길이가 고정되어야 해서 다양한 길이의 입력 데이터를 처리하지 못하는 치명적인 단점이 있다. 그리고 고차원의 입력 데이터를 처리하기에는 너무 많은 파라미터와 연산이 필요해서 비효율적이다.
그래서 시계열 입력에는 LSTM, 2차원 영상 입력에는 CNN이 진리로 받아들여졌다. 둘 다 고정된 수의 파라미터로 다양한 길이의 입력을 처리할 수 있고 입력 길이에 비례하는 연산량을 가졌다.
Transformer는 MLP로 유연성과 효율성을 모두 만족하는 구조를 만들어냈다. Transformer에서는 학습가능한 파라미터의 수는 입력 데이터의 길이와는 아무 상관이 없다. Transfomer에서 학습 가능한 파라미터는 linear layer에만 있는데, 단일 linear layer가 모든 token이나 embedding에 대해 동일하게 적용된다. 마치 CNN처럼. Transformer를 linear가 아닌 conv 레이어로 구현할수도 있을것 같다. 그래서 linear layer에서는 입력 데이터 길이에 비례한 연산량이 들어간다. 다만 attention 연산과정에서 입력 데이터 길이의 제곱에 비례하는 연산이 들어가긴 한다.
이렇게 단점을 해결하고 나니 장점이 보인다. MLP는 모든 종류의 데이터를 처리할 수 있는 잠재력이 있다. 시계열이든 영상이든. MLP가 모든 입력 데이터를 한번에 연결하므로 성능 측면에서도 유리하다.
게다가 transformer에는 attention이 있다. 다양한 입력 토큰으로부터 나오는 이전 레이어의 value들을 관심(attention)있는 다른 value들과의 가중 평균으로 새로운 value들을 만들어낸다. Value들을 섞어놓고 다음 MLP에 입력으로 들어가 처리가 된다. 이러한 과정을 거치다보면 단순히 linear나 conv 레이어를 반복하는 것보다는 의미있는 것에 집중한 양질의 feature가 만들어질 것이라는 기대감이 생긴다.