[Cpp] Smart Pointers
Smart Pointers
C++은 C언어로부터 유래됐고 C언어는 포인터를 이용해 메모리를 수동으로 관리한다. 포인터에 적절한 메모리를 할당하는 것(메모리 효율성), 해제하는 것(메모리 누수 방지), 포인터를 할당된 메모리 범위 내에서 사용하는 것과 메모리가 해제됐는지 확인하는 것(메모리 에러 및 버그 관리)가 모두 프로그래머의 책임이다. 포인터는 수많은 버그를 양산하는 원인이지만 메모리 관리를 위한 비용이 전혀 없기 때문에 프로그래머가 전지(全知)한 상태에서 모든 경우의 수를 고려해 적절히 짠다면 가비지 컬렉터(garbage collector)를 사용하는 언어보다 빠르고 효율적으로 동작할 수 있다. 하지만 여러 사람이 협업하는 대규모 프로젝트에서 메모리를 완벽하게 관리하는 것은 어려운 일이다.
다음은 원시 포인터를 사용하기 힘든 이유들이다.
- 선언만 봐서는 하나의 객체인지 배열인지 구분할 수 없다. (
int []타입을int*타입으로 치환 가능) - 선언만 봐서는 누가 포인터의 피지칭 객체를 소유하고 있는지 알 수 없고 따라서 누가 객체를 파괴해야 하는지 알 수 없다.
- 객체를 사용자가 직접 파괴해야 한다는 것을 안다고 해도 어떻게 파괴해야 하는지 알 수 없다.
delete를 사용해야 할 수도 있고 다른 파괴 매커니즘을 이용해야 할 수도 있다. -
delete를 이용해 파괴해야 한다고 해도, 1번 때문에delete로 단일 객체를 파괴해야 하는지delete []로 배열을 파괴해야 하는지 알 수 없다. - 포인터가 피지칭 객체를 소유하고 있으며 그것을 파괴하는 구체적인 방법을 알아냈다고 하더라도, 코드의 모든 경로에서 파괴가 정확히 한번 일어남을 보장하기 어렵다. (이를테면 예외 때문에) 파괴가 일어나지 않는 경로가 하나라도 있으면 자원 누수가 발생하며, 파괴를 여러 번 수행하는 것은 미정의 결과를 낳는다.
- 대체로, 포인터가 피지칭 객체를 잃었는지 알아낼 방법이 없다. 포인터가 가리키는 주소에 유효한 객체가 존재하는지 확인할 수 없다.
그래서 C++11에서는 메모리를 자동으로 관리하여 메모리 누수 및 잘못된 접근 가능성을 크게 줄인 스마트 포인터(smart pointer)라는 템플릿 클래스가 생겼다. (기존의 포인터를 원시 포인터(raw pointer)라고 부르기로 한다.) 스마트 포인터는 내부적으로 원시 포인터와 그에 연결된 메모리를 관리하고 있으며 스마트 포인터 객체가 파괴될 때 혹은 더 이상 사용되지 않을 때 자동으로 메모리를 해제해준다. 스마트 포인터는 원시 포인터에 비해 성능이 2~3배 차이가 나지만 요즘 PC 성능에서는 큰 비용이 아니고 사용의 안전성과 편의성을 보장하므로 생산성 향상에 큰 도움이 된다. 이제는 원시 포인터는 프로그램의 원리를 배우는 정도로만 사용하고 실제 코딩에서는 스마트 포인터나 이후에 배울 컨테이너(container)를 사용하는 것이 적극 권장된다.
스마트 포인터는 네 가지가 있는데 그 중 auto_ptr은 제대로 된 C++11이라 할 수 없으므로 제외하고 나머지 세 가지 스마트 포인터에 대해 알아본다.
- unique_ptr
- shared_ptr
- weak_ptr
1. unique_ptr
참고자료: (Modern Effective C++) 항목 18. 소유권 독점 자원 관리에는 std::unique_ptr를 사용하라
스마트 포인터를 사용할 때 가장 먼저 고려해야 할 것은 unique_ptr이다. unique_ptr은 원시 포인터와 거의 같은 크기고 사용법도 거의 비슷하게 사용할 수 있다. unique_ptr은 shared_ptr에 비해 작고 빠르다.
unique_ptr은 항상 자신이 가리키는 객체를 독점적으로 소유한다. 그래서 unique_ptr은 복사가 허용되지 않는 이동 전용 형식(move-only type)이다. 널(null)이 아닌 unique_ptr은 소멸시 자신이 가리키는 객체를 파괴한다. unique_ptr이 어떻게 앞서 말한 원시 포인터의 위험성을 제거하는지 살펴보자.
- 선언만 봐서는 하나의 객체인지 배열인지 구분할 수 없다.
 unique_ptr은 단일 객체와 객체 배열을 구분해서 선언한다. 정수 타입인 경우
unique_ptr은 단일 객체와 객체 배열을 구분해서 선언한다. 정수 타입인 경우 std::unique_ptr<int>, std::unique_ptr<int[]>두 가지로 명확히 구분한다. - 선언만 봐서는 누가 포인터의 피지칭 객체를 소유하고 있는지 알 수 없다. unique_ptr은 객체를 독점 소유하므로 어떤 유효한 객체를 가리키는 unique_ptr 객체가 있다면 그것이 객체를 소유하고 있는 것이다.
- 객체를 사용자가 직접 파괴해야 한다는 것을 안다고 해도 어떻게 파괴해야 하는지 알 수 없다. 기본적으로 delete로 파괴하고 다른 방법이 필요한 경우에는 deleter 객체를 지정할 수 있다.
-
delete를 이용해 파괴해야 한다고 해도, 1번 때문에delete로 단일 객체를 파괴해야 하는지delete []로 배열을 파괴해야 하는지 알 수 없다. 1과 동일한 대답 - 코드의 모든 경로에서 파괴가 정확히 한번 일어남을 보장하기 어렵다. unique_ptr이 가리키는 객체는 힙(heap)에 있어서 예외 발생시 파괴되지 않을 수 있지만 unique_ptr 자체는 스택(stack)에 선언되므로 예외 발생시 스택 풀기(stack unwinding)과정에서 unique_ptr의 소멸자가 호출된다. 참고
- 포인터가 피지칭 객체를 잃었는지 알아낼 방법이 없다. unique_ptr 이 가리키는 객체가 해제되면 반드시 내부 원시 포인터가
nullptr을 가지게 되므로nullptr과의 비교를 통해 확인할 수 있다.
1.1. 생성
참고자료: (Modern Effective C++) 항목 21. new를 직접 사용하는 것보다 std::make_unique와 std::make_shared를 선호하라
생성 방식
unique_ptr을 생성하는 방식은 unique_ptr의 생성자를 사용하는 방법과 make_unique 함수를 쓰는 방법이 있다.
#include <iostream>
#include <memory>
int main() {
// unique_ptr 생성자 사용, 객체 생성자 인수 없음
std::unique_ptr<int> up1(new int);
// make_unique 사용, 객체 생성자 인수 없음
std::unique_ptr<int> up2 = std::make_unique<int>();
// unique_ptr 생성자 사용, 객체 생성자 인수 입력
std::unique_ptr<int> up3(new int(3));
// make_unique 사용, 객체 생성자 인수 입력
std::unique_ptr<int> up4 = std::make_unique<int>(5);
// make_unique 사용, auto 타입 활용 -> 추천!!
auto up5 = std::make_unique<int>(5);
}
unique_ptr의 생성자를 사용할 때는 new 연산자를 이용해 객체를 직접 생성해서 그 포인터를 넘겨준다. 이보다는 make_unique 함수를 쓰는 것이 권장되는데 그 이유는 다음과 같다.
- 생성자를 사용하면 타입을 두 번 써야 한다.
up1을 만들기 위해int타입을 두 번 쓰지만up5에서는 auto를 이용하므로int를 한 번만 쓴다.new연산자를 이용해 객체를 직접 생성하는 경우 auto를 쓸 수 없다. - 생성자에서는 원시 포인터를 받으므로 이런 코드도 가능하다:
int* iptr=new int; unique_ptr<int> up(iptr);이 경우 포인터의 소유권이 분산되므로 unique_ptr의 목적대로 동작하지 않을 수 있다.
참고로 shared_ptr도 마찬가지로 make_shared 함수를 쓰는 것이 좋은데 그 이유는 위에서 말한 이유 외에 두 가지가 더 있다. 그에 대해서는 shared_ptr과 함께 설명하기로 한다.
Custom Deleter 사용
unique_ptr에서는 객체 파괴시 기본적으로 내부의 원시 포인터에 delete 연산자를 적용하고 nullptr을 대입하지만 추가적인 처리가 필요한 경우 이를 처리할 수 있는 커스텀 삭제자(custom deleter)를 지정할 수 있다. 커스텀 삭제자로는 functor, lambda function 처럼 호출 가능한(callable) 객체를 사용할 수 있다.
다음은 커스텀 삭제자를 지정한 예시다. 예시에서 커스텀 삭제자로 Deleter라는 클래스를 구현하였고 이 클래스에는 operator()가 정의되어 있으므로 객체를 함수처럼 호출 가능하다(functor). 입력 인자로는 삭제하고자 하는 객체의 원시 포인터를 받아야 한다. 삭제자 클래스는 unique_ptr의 템플릿 인수로 넣으면 내부에서 자동으로 삭제자 객체를 생성해준다. 혹은 명시적으로 삭제자를 생성하여 입력할 수도 있다.
#include <iostream>
#include <memory>
struct Object {
Object(int v_) : v(v_) { std::cout << "Object constructor\n"; }
~Object() { std::cout << "Object destroyer\n"; }
int v;
};
struct Deleter {
Deleter() { std::cout << "create Deleter\n"; }
void operator()(Object *o)
{
std::cout << "Deleter operator()\n";
delete o;
}
};
int main() {
{
std::cout << "===== implicit creation of deleter\n";
std::unique_ptr<Object, Deleter> up1(new Object(1));
}
{
std::cout << "===== explicit creation of deleter\n";
Deleter deleter;
std::unique_ptr<Object, Deleter> up2(new Object(1), deleter);
}
}
===== implicit creation of deleter Object constructor create Deleter Deleter operator() Object destroyer ===== explicit creation of deleter create Deleter Object constructor Deleter operator() Object destroyer
1.2. 사용법
unique_ptr의 사용법을 다음 예제를 통해 알아보자.
#include <iostream>
#include <memory>
#include <cassert>
class MyString {
std::string str;
public:
MyString(std::string str_) : str(str_) { std::cout << "[create] " << str << std::endl; }
~MyString() { std::cout << "[delete] " << str << std::endl; }
void print() const { std::cout << "[print] " << str << std::endl; }
void set(std::string newstr) {
str = newstr;
std::cout << "[set] " << str << std::endl;
}
};
void print_mystring(const std::unique_ptr<MyString> mystr) {
std::cout << "[print_mystring]";
/* 내부 함수 호출: 일반 포인터와 사용법 동일: ->, * operator */
mystr->print();
(*mystr).print();
}
int main() {
/* 생성 */
auto foo = std::make_unique<MyString>("foo");
auto bar = std::make_unique<MyString>("bar");
/* (중요!) std::move를 이용한 객체 이동 */
print_mystring(std::move(foo));
/* unique_ptr은 복사 불가! */
// print_mystring(foo);
/* nullptr 확인 */
// foo은 함수 내부로 이동했으므로 객체 소유권을 잃고 nullptr만 가지고 있음
// nullptr과의 비교 연산 지원: ==, !=
if (foo != nullptr)
foo->print(); // 실행되면 Segmentation fault 에러 발생
if (foo == nullptr)
std::cout << "foo is nullptr\n";
/* get(): 내부 원시 포인터 접근 */
MyString *rpstr = bar.get();
rpstr->set("bar2");
bar->print();
// WARNING!! 원시 포인터를 삭제하면 bar 소멸시 Segmentation fault 에러 발생
// delete rpstr;
/* 참조를 이용한 자원 공유는 허용된다. */
MyString &refshare = *bar;
refshare.print();
/* release(): 자원 해제(delete) */
bar.release();
assert(bar == nullptr);
/* reset(T *ptr = nullptr): 자원 해제 및 새로운 자원 할당 */
bar.reset(new MyString("bar3"));
bar->print();
bar.reset();
assert(bar == nullptr);
}
생성·이동·복사
객체 생성에 대해서는 앞서 설명했듯이 make_unique 함수를 쓰는게 낫다. unique_ptr 객체를 다른 함수에 전달할 때는 (혹은 다른 unique_ptr 객체에 할당할 때는) 반드시 move 함수를 통해 소유권을 넘겨줘야 한다. 소유권을 넘겨준다는 것은 내부 포인터를 다른 객체에 넘겨주고 자신은 nullptr이 되는 것이다.
아래 코드 마지막 줄처럼 객체 자체를 넘겨주면 입력 인자 전달 과정에서 객체 복사를 시도하는데 unique_ptr은 복사 생성자를 삭제 선언 했으므로 복사는 컴파일되지 않는다. print_mystring의 입력인자를 참조 타입으로 하면 마지막 줄도 가능하긴 하다.
auto foo = std::make_unique<MyString>("foo");
auto bar = std::make_unique<MyString>("bar");
print_mystring(std::move(foo));
// print_mystring(foo);
nullptr 확인
unique_ptr은 소유권을 넘겨주고 나면 nullptr만 남게 되므로 이후에는 사용해서는 안된다. unique_ptr이 객체를 소유하고 있는지 확신할 수 없다면 사용하기 전에 확인할 필요가 있다. unique_ptr은 nullptr과 비교연산자(==, !=)를 지원하여 get()함수로 원시 포인터를 꺼내지 않고 바로 nullptr과 비교할 수 있다.
if (foo != nullptr)
foo->print();
if (foo == nullptr)
std::cout << "foo is nullptr\n";
nullptr은 C++11에서 도입된 널 포인터 리터럴(null pointer literal)이다. 오로지 빈 포인터를 확인하기 위한 값이며 C++11 이전에 포인터에 0이나 NULL을 넣어서 빈 포인터를 확인하는 것보다 가독성이 좋고 0이라는 int 타입과 헷갈리지 않게 된다. 참고
또한 여기서는 unique_ptr인 foo에서 -> 연산자를 통해 내부 객체의 멤버함수를 직접 접근하는 것을 볼 수 있다. foo->ptr->print() 가 아니다. 이것은 unique_ptr에서 연산자 오버로딩을 통해 가능하다.
template <typename T>
class unique_ptr {
T* ptr;
T* operator->() { return ptr; }
...
}
int main() {
auto foo = std::make_unique<MyString>("foo");
foo->print(); // it is interpreted as (foo.operator->())->print() by complier
}
자원 공유
unique_ptr은 원래 자원을 독점 소유하도록 만들어졌지만 약간의 구멍(?)은 남겨뒀다. 내부 포인터를 외부에서 접근한다거나 내부 객체에 대한 참조 변수를 만들 수 있다. 다만 내부 객체의 수명이 다했을 때 발생하는 오류는 프로그래머의 책임이니 주의해서 써야한다.
MyString *rpstr = bar.get();
rpstr->set("bar2");
bar->print();
// WARNING!! 원시 포인터를 삭제하면 bar 소멸시 Segmentation fault 에러 발생
// delete rpstr;
MyString &refshare = *bar;
refshare.print();
자원 해제
스마트 포인터기 때문에 자원 해제를 명시적으로 해줄 필요는 자주 없지만 그런 기능을 지원하고 있다. 또한 내부 자원을 해제하고 새로운 자원을 받기도 한다.
bar.release();
assert(bar == nullptr);
/* reset(T *ptr = nullptr): 자원 해제 및 새로운 자원 할당 */
bar.reset(new MyString("bar3"));
bar->print();
bar.reset();
assert(bar == nullptr);
1.3. Factory 함수 예시
unique_ptr이 전형적으로 사용되는 예시는 팩터리(factory) 함수의 반환 형식으로 쓰이는 것이다. 다음과 같은 함수 계통 구조가 있다고 하자.
- Investment (base)
- Stock
- Bond
- RealEstate
이런 계통 구조에 대한 팩터리 함수는 흔히 힙에 객체를 생성하고 그 포인터를 돌려준다. 그 객체를 사용하지 않게 됐을때 삭제하는 것은 호출자의 책임이므로 unique_ptr은 이런 용법에 적합하다. 다음은 Investment라는 기반 클래스와 Bond, Stock, RealEstate라는 하위 클래스가 있을 때 입력 조건에 따라 클래스 객체를 unique_ptr에 담아 반환해주는 makeInvestment 함수를 구현한 것이다.
#include <iostream>
#include <memory>
#include <cassert>
struct Investment {
Investment(int price_, std::string what_) : price(price_), what(what_) {}
// 기반 클래스의 소멸자는 반드시 가상 함수로 선언한다. (virtual)
virtual ~Investment() {}
int price;
std::string what;
void print(std::string title) {
std::cout << title << " " << price << " " << what << std::endl;
}
};
struct Bond : public Investment {
Bond(int price_, std::string what) : Investment(price_ + 1, what)
{ print("create Bond"); }
virtual ~Bond() { print("destroy Bond"); }
};
struct Stock : public Investment {
Stock(int price_, std::string what) : Investment(price_ + 2, what)
{ print("create Stock"); }
virtual ~Stock() { print("destroy Stock"); }
};
struct RealEstate : public Investment {
RealEstate(int price_, std::string what) : Investment(price_ + 3, what)
{ print("create RealEstate"); }
virtual ~RealEstate() { print("destroy RealEstate"); }
};
void make_log(const Investment *pinv) {
std::cout << "make_log\n";
}
template <typename... Ts>
auto makeInvestment(std::string name, Ts&&... params) {
auto del_inv = [](Investment *pinv)
{
make_log(pinv);
delete pinv;
};
// 아직 객체를 생성하지 않고 nullptr로 초기화
std::unique_ptr<Investment, decltype(del_inv)> upinv(nullptr, del_inv);
// 입력 인자에 따라 다른 객체 생성
if (name == "Bond")
upinv.reset(new Bond(std::forward<Ts>(params)...));
else if (name == "Stock")
upinv.reset(new Stock(std::forward<Ts>(params)...));
else if (name == "RealEstate")
upinv.reset(new RealEstate(std::forward<Ts>(params)...));
return upinv;
}
int main() {
auto upstock = makeInvestment("Stock", 10, "Nvidia");
auto uprestate = makeInvestment("RealEstate", 10, "Kangnam");
}
create Stock 12 Nvidia create RealEstate 13 Kangnam make_log destroy RealEstate 13 Kangnam make_log destroy Stock 12 Nvidia
팩터리 함수의 구현 요소들을 하나씩 살펴보자.
-
del_inv는 unique_ptr에 들어가는 커스텀 삭제자다. 커스텀 삭제자를 쓰려면make_unique()함수 대신 unique_ptr 생성자를 써야한다. 삭제자에서는 객체를 파괴하기 전 로그를 기록한다. - 삭제자는 람다 표현식으로 구현했는데 functor를 사용하는 것보다 간단하게 callable 객체를 만들 수 있다.
- 커스텀 삭제자는 기반 타입으로 원시 포인터를 받아 삭제하는데 이때
Investment의 소멸자가 가상 소멸자여야만 delete 실행 시 하위 클래스의 소멸자가 호출된다. - 커스텀 삭제자의 타입은 unique_ptr의 템플릿 인자로 들어가야 하는데 이를
decltype(del_inv)로 간단히 해결했다. 굳이 이 람다 표현식의 타입을 알아야할 필요가 없다. -
new로 생성한 객체의 소유권을upinv에 부여하기 위해reset()을 사용한다. -
makeInvestment함수에 전달된 인수들을 생성자에 손실 없이 완벽하게 전달하기 위해std::forward를 사용했다. - 생성자의 입력 인자 타입과 개수에 상관없이 작동하는 함수를 만들기 위해 variadic template 을 사용했다.
Variadic Template
팩터리 함수를 봤을 때 여기저기 보이는 ...(ellipsis)가 처음본 사람에게는 이상하게 보일 수 있다. 코드를 쓰다가 만건가? 그건 아니다 ...은 여러개의 입력인자들을 묶어놓은 parameter pack을 사용할 때 쓰이는 문법이다.
템플릿을 정의할 때 typename... Ts는 여러개의 여러가지 타입을 동시에 받을 수 있는 템플릿 타입이며 parameter pack이라 한다. parameter pack을 이용하는 템플릿을 variadic template이라 한다. 쉽게 말해 Ts는 함수의 입력인자에 따라 자동으로 int, int가 될 수도 있고 int, double, string이 될 수도 있다. 이를 이용하면 파이썬의 print(10, 3.14, "hello") 같은 함수를 구현할 수도 있다. 링크의 내용을 공부해보자.
위 팩터리 함수 예시에서 모든 생성자의 입력인자가 동일하기 때문에 굳이 어렵게 variadic template을 써야하는지 의문이 들 수 있다. 아래와 같이 쉽고 간단하게 구현 할 수도 있는데 말이다.
auto makeInvestment(std::string name, int&& asset, std::string&& what)
{
// ... 생략 ...
if (name == "Bond")
upinv.reset(new Bond(asset, what));
}
auto upstock = makeInvestment("Stock", 10, "Nvidia");
팩터리 함수에서 variadic template을 쓰는 장점은 다음과 같다.
- makeInvestment 함수에서 생성자의 입력인자를 몰라도 된다.
- 명시적 타입을 쓰는 경우 입력인자가 여러개인 경우 팩터리 함수의 정의나 객체 생성 코드가 길어질 수 있지만 variadic template은 일정하다.
- 객체 생성자의 입력인자가 변경될 경우 variadic template을 쓰면 함수 호출 부분만 바꾸면 된다. 반면 쓰지 않으면 팩터리 함수 내부에서 고쳐야 할 부분이 많다.
마치 파이썬에서 def func(*args, **kwargs)를 쓰는 것과 같다.
2. shared_ptr
shared_ptr은 자원의 소유권을 공유할 수 있는 스마트 포인터다. 자원을 공유할 때 중요한 점은 “생성된 객체를 언제 누가 파괴할 것인가?” 다. unique_ptr은 소유권을 공유하지 않으니 unique_ptr (껍데기) 객체가 파괴될 때 내부 피지칭 객체를 파괴하면 된다. 반면 shared_ptr 파괴 시점은 세 가지로 표현할 수 있다.
- 어떤 객체가 더 이상 사용되지 않을 때
- 피지칭 객체에 대한 소유권을 공유하는 shared_ptr 객체가 모두 파괴될 때
- 소유권을 가지는 shared_ptr 객체들 중 마지막 shared_ptr 객체가 파괴될 때
자바, 파이썬 같은 경우는 메모리를 전역적으로 관리하는 garbage collector가 있다. 그런데 garbage collector가 언제 사용하지 않는 메모리를 해제할 지 프로그래머는 알 수 없다. 그것은 인터프리터 내부에서 전체적인 최적화를 고려하여 결정할 것이므로 꼭 위에서 말한 파괴 시점과 일치하지 않을 수 있다.
C++ 자체가 control freak을 위한 언어인데 아무리 메모리 관리를 효과적으로 하고 싶다고 해도 garbage collector 같은 것을 쓸리 없다. 대신 파괴시점을 확정적으로 예측할 수 있는 shared_ptr을 만들었다.
2.1. 참조 횟수 관리
같은 객체에 대한 소유권을 공유하는 shared_ptr의 개수는 참조 횟수(reference count)에 의해 관리된다. 처음 객체가 생성될 때 참조 횟수는 1이며 그 객체를 가리키는 shared_ptr이 늘어나면 참조 횟수도 늘어난다. 피지칭 객체를 가리키는 마지막 shared_ptr이 파괴되면 참조 횟수는 0이 되고 이때 피지칭 객체가 파괴된다. 참조 횟수가 증감하는 경우는 다음과 같다.
- (+1) 최초 객체 생성 (construction)
- (+1) 복사 생성 (copy construction)
- (+1) 복사 대입 (copy assigment, lhs 입장)
- (-1) 복사 대입 (copy assigment, rhs 입장)
- (-1) shared_ptr 파괴
- (-1) shared_ptr 리셋
shared_ptr의 현재 참조 횟수는 use_count()라는 함수로 확인할 수 있다. 다음은 다양한 상황에서 참조 횟수의 증감을 확인하는 예시다.
#include <iostream>
#include <memory>
#include <cassert>
struct Foo
{
std::string str;
Foo(const std::string str_) : str(str_) {}
};
void print(std::shared_ptr<Foo> sptr) {
std::cout << "4. In-function: " << sptr->str << " ref count= " << sptr.use_count() << std::endl;
}
int main() {
// +1 생성
auto sp1 = std::shared_ptr<Foo>(new Foo("foo"));
std::cout << "1. Construct: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
// +1 복사 생성
auto sp2 = sp1;
std::cout << "2. Copy construct: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
std::cout << "2. Copy construct: " << sp2->str << " ref count= " << sp2.use_count() << std::endl;
// +1 복사 대입
auto sp3 = std::shared_ptr<Foo>(nullptr);
sp3 = sp1;
std::cout << "3. Copy assignment: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
std::cout << "3. Copy assignment: " << sp3->str << " ref count= " << sp3.use_count() << std::endl;
// +-1 함수 입력
print(sp1);
std::cout << "4. Out-function: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
// 0 이동 생성 -> sp3 파괴
auto sp4 = std::move(sp3);
assert(sp3 == nullptr);
std::cout << "5. Move: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
std::cout << "5. Move: " << sp4->str << " ref count= " << sp4.use_count() << std::endl;
// -1 다른 객체 대입 -> sp4 파괴
sp4 = std::shared_ptr<Foo>(new Foo("bar"));
assert(sp4 == nullptr);
std::cout << "6. Assign other: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
std::cout << "6. Assign other: " << sp4->str << " ref count= " << sp4.use_count() << std::endl;
// -1 reset -> sp2 파괴
sp2.reset();
assert(sp2 == nullptr);
std::cout << "7. Reset: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
{
// +1 복사 생성
auto sp5 = sp1;
std::cout << "8. Copy assignment: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
}
// -1 shared_ptr 파괴 -> sp5 파괴
std::cout << "8. Destroy copy: " << sp1->str << " ref count= " << sp1.use_count() << std::endl;
}
2.2. shared_ptr의 비용
shared_ptr은 원시 포인터에 비해 참조 횟수 관리를 위한 추가적인 비용이 필요하다. 어느정도의 비용이 드는지 설명하기 위해 shared_ptr의 내부 구조를 보자.
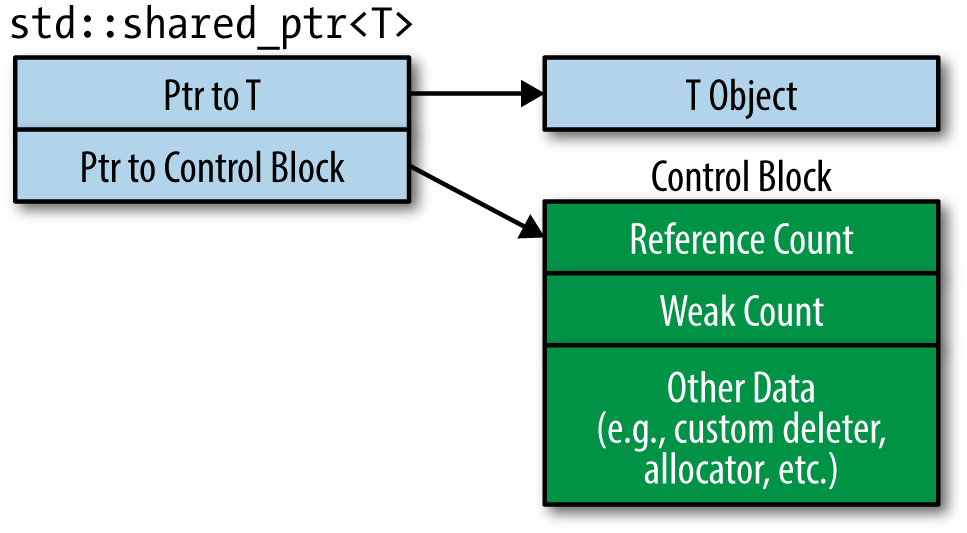
shared_ptr은 두 개의 포인터로 이루어져있다. 하나는 원래 관리하고자 하는 피지칭 객체(T Object)가 있고 다른 하나는 이를 관리하기 위한 제어 블록(Control Block)이 있다. 관리하는 객체 하나당 제어 블록도 하나만 있어야 하므로 제어 블록도 동적으로 할당되고 shared_ptr에서는 그에 대한 포인터만 가지고 있다.
제어 블록에는 참조 횟수 뿐만 아니라 약한 횟수(weak count)와 커스텀 삭제자, 할당자 등이 있다. 약한 횟수는 shared_ptr을 보조하는 weak_ptr을 위한 것이고, 커스텀 할당자와 삭제자는 객체를 생성하고 삭제하는 과정을 정의한 함수 객체다. 커스텀 할당자, 삭제자는 데이터를 포함할 수 있기 때문에 제어 블록의 크기는 얼마든지 늘어날 수도 있다.
성능에 영향을 미치는 다른 요인으로 원자적 연산과 가상 함수 사용이 있다. 여러 스레드에서 동시에 shared_ptr의 참조 횟수를 증감시키려 하면 미정의 결과가 나올수 있으므로 참조 횟수를 수정하는 일은 원자적(atomic) 연산으로 해야한다. 대체로 원자적 연산은 비원자적 연산보다 느리다. 제어 블록의 구현에서 상속이 사용되고 가상 함수도 있으므로 이에 대한 비용도 추가된다. 가상함수를 쓰면 미미하게 메모리 사용과 연산이 증가하긴 하지만 더 중요한 것은 인라인(inline) 최적화를 막는다는 것이다.
이렇게 보면 shared_ptr을 사용하는 부담이 큰 것 같지만 사실 그렇진 않다. 전형적인 경우 (기본 할당자와 삭제자를 쓸 때) std::make_shared 함수를 쓰면 제어 블록은 워드 세 개 정도의 크기다. 참조 횟수 조작이 필요한 연산에는 원자적 연산 한 두 개가 더 소비되나 임베디드 환경이 아닌 이상 별 의미는 없다. 가상함수는 제어블록을 파괴할 때만 사용되므로 자주 쓰이는 것은 아니다.
이러한 적은 비용을 치르는 대신, 소유권을 공유하는 동적 할당 자원의 수명이 자동으로 관리된다는 이득이 생긴다. 우선 소유권 공유가 필요한지 생각해보고 독점 소유권으로도 충분하다면 unique_ptr이 나은 선택이다. unique_ptr은 언제든 shared_ptr로 업그레이드 가능하지만 그 역은 불가능하다.
unique_ptr은 배열 객체 관리가 가능하지만 shared_ptr은 단일 객체 관리만을 염두해두고 설계됐다. shared_ptr<T[]>와 같은 배열 객체는 지원하지 않는다. 배열 관리는 std::array, vector 등 더 나은 대안이 있다.
2.3. 생성 방식
unique_ptr과 마찬가지로 shared_ptr도 두 가지 방식이 있다.
- 기본 생성자: new를 사용하며, 커스텀 삭제자와 할당자를 지정할 수 있다.
-
std::make_shared<T>: 기본적으로 권장되는 방법, 객체와 제어 블록 메모리를 한번에 연결하여 할당하여 더 효율적이고 메모리 누수 위험이 없다.
다음은 shared_ptr의 생성과 관련된 예시다.
#include <iostream>
#include <memory>
#include <vector>
#include <exception>
struct MyString
{
std::string str;
MyString(std::string s) : str(s) {}
};
void process(std::shared_ptr<MyString> ptr, int a) {}
int main()
{
auto my_deleter = [](MyString *mstr) {
std::cout << "delete " << mstr->str << std::endl;
delete mstr;
};
auto exception_thrower = []() {
throw std::exception();
return 0;
};
// 1. 기본 생성자
std::shared_ptr<MyString> sp1(new MyString("hello"));
// 2. custom deleter 지정 (타입 똑같음)
std::shared_ptr<MyString> sp2(new MyString("shared"), my_deleter);
// 2-1. custom deleter 지정한 unique_ptr (타입이 다름)
std::unique_ptr<MyString, decltype(my_deleter)> ups(new MyString("unique"), my_deleter);
// 3. make_shared 사용
auto sp3 = std::make_shared<MyString>("pointer");
// 4. 메모리 누수 가능
try {
process(std::shared_ptr<MyString>(new MyString("exception")), exception_thrower());
}
catch (std::exception e) {
std::cout << "exception happened\n";
}
// 5. 타입이 같으므로 vector에 넣어서 사용
std::vector<std::shared_ptr<MyString>> vsp = {sp1, sp2, sp3};
std::string sentence;
for (const auto &sp : vsp)
sentence += sp->str + " ";
std::cout << "sentence: " << sentence << std::endl;
}
1, 2, 3은 shared_ptr 생성의 세 가지 경우를 보여준다. 2-1은 unique_ptr과의 차이점인데 unique_ptr에서 커스텀 삭제자를 지정하는 경우 삭제자의 타입이 unique_ptr의 타입에 포함된다. 반면 shared_ptr은 커스텀 삭제자가 입력인자로 들어갈 뿐 포인터 타입은 shared_ptr<MyString> 그대로다. 이것은 좀 더 유연한 코딩을 가능하게 한다. 같은 타입의 객체를 가지지만 삭제자의 유무나 삭제자의 타입이 다른 shared_ptr들의 타입이 같으므로 하나의 container에 담을 수 있다. 5에서 보여주듯 삭제자가 있는 sp2와 삭제자가 없는 sp1, sp3이 하나의 vector 안에 담기는 것을 볼 수 있다.
4는 메모리 누수 가능성을 가진 코드다. 일반적으로 예상하기로는 try 내부의 코드 실행 순서는 다음과 같을 것이다.
- new MyString()
- shared_ptr 생성
- exception_thrower()
하지만 컴파일러 최적화에 의해 코드의 실제 실행 순서는 바뀔 수 있다. 만약 2번과 3번이 바뀐 상태에서 위와 같이 3번에서 예외가 발생한다면 어떻게 될까? 1번에서 이미 메모리 할당은 됐는데 그 메모리가 shared_ptr에 들어가기 전에 예외가 발생한다면 그 메모리는 해제될 수 없다. 이때 make_shared를 쓰면 이런 문제가 발생하지 않는다. process(std::make_shared<MyString>("exception"), exception_thrower());
2.4. 사용예시
소유권을 공유해야 하는 객체는 어떤 경우에 필요할까? 생각보다 한정적이다. 대부분의 순차적인 처리과정을 거치는 데이터는 unique_ptr로 가능하다. 그러나 가끔은 하나의 자원을 여러 곳에 공유시킨 뒤 처리하는 것이 편할 때가 있다. 멀티 스레드(프로세스) 프로그램이 대표적이다. 멀티 스레드가 아니더라도 여러 곳에서 공통적으로 쓰이는 객체를 독점 소유권으로 관리하면 불필요한 인자 전달 과정만 길어진다. 예를 들어, foo->bar->baz 로 이어지는 객체 구조가 있고 또한 spam->ham 객체 구조가 있는데 baz라는 데이터를 ham에게 함수를 통해 전달하려면 여러 단계의 전달과정이 필요하다. 이런 경우에는 bar와 ham에서 baz라는 데이터를 포인터를 통해 공유하는 것이 편리하다.
다음은 그러한 예시를 간단하게 구현한 것이다.
#include <iostream>
#include <memory>
struct WeatherInfo {
std::string weather;
WeatherInfo(std::string w) : weather(w) {}
};
struct WeatherForecaster {
std::shared_ptr<WeatherInfo> wtsp;
WeatherForecaster(std::shared_ptr<WeatherInfo> w) : wtsp(w) {}
void update(int seed) {
if (wtsp == nullptr)
std::cout << "weather pointer is null\n";
else {
wtsp->weather = (seed % 2) ? "rainy" : "sunny";
std::cout << "weather is updated to " << wtsp->weather
<< ", count=" << wtsp.use_count() << std::endl;
}
}
};
struct Scheduler {
std::shared_ptr<WeatherInfo> wtsp;
std::string action;
Scheduler(std::shared_ptr<WeatherInfo> w) : wtsp(w) {}
void check_action() {
if (wtsp->weather == "sunny")
action = "take a hat";
else if (wtsp->weather == "rainy")
action = "take an umbrella";
else
action = "no idea";
std::cout << "check action: " << action << ", count=" << wtsp.use_count() << std::endl;
}
};
int main() {
auto wtsp = std::make_shared<WeatherInfo>("sunny");
WeatherForecaster forecaster(wtsp);
Scheduler scheduler(wtsp);
int i = 0;
while (++i <= 2) {
forecaster.update(i);
scheduler.check_action();
}
wtsp.reset(new WeatherInfo("cloudy"));
forecaster.update(0);
scheduler.check_action();
return 0;
}
weather is updated to rainy, count=3 check action: take an umbrella, count=3 weather is updated to sunny, count=3 check action: take a hat, count=3 weather is updated to sunny, count=2 check action: take a hat, count=2
WeatherInfo는 WeatherForecaster와 Scheduler 사이에서 공유되는 객체다. forecaster에서 update를 하면 굳이 그 결과를 함수를 통해 전달하지 않아도 scheduler에서 바로 쓸 수 있다.
그런데 만약에 최초에 생성한 shared_ptr을 파괴한다면 어떻게 될까? forecaster와 scheduler에서 가지고 있는 객체도 파괴될까? 그건 아니다. main에서 생성한 shared_ptr을 파괴해도 이미 복사본이 다른 객체에 들어가 있으므로 처음에 만든 객체는 남아있게 된다.